Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generation

Originating from the diffusion phenomenon in physics that describes particle movement, the diffusion generative models inherit the characteristics of stochastic random walk in the data space along the denoising trajectory. However, the intrinsic mutual interference among image regions contradicts the need for practical downstream application scenarios where the preservation of low-level pixel information from given conditioning is desired (e.g., customization tasks like personalized generation and inpainting based on a user-provided single image). In this work, we investigate the diffusion (physics) in diffusion (machine learning) properties and propose our Cyclic One-Way Diffusion (COW) method to control the direction of diffusion phenomenon given a pre-trained frozen diffusion model for versatile customization application scenarios, where the low-level pixel information from the conditioning needs to be preserved. Notably, unlike most current methods that incorporate additional conditions by fine-tuning the base textto-image diffusion model or learning auxiliary networks, our method provides a novel perspective to understand the task needs and is applicable to a wider range of customization scenarios in a learning-free manner. Extensive experiment results show that our proposed COW can achieve more flexible customization based on strict visual conditions in different application settings.
The physical diffusion is an intrinsically stochastic process with no directional constraints, the same characteristic should be preserved in diffusion models in machine learning, which is also believed to model a random walk in the data space. In this work, we design an analytical experiment to explicitly disclose this particle movement in image generation diffusion models in a straightforward way. We inverse pictures of pure gray and white back to xt, merge them together with different layouts, and then regenerate them back to x0 via deterministic denoising. Different columns indicate different replacement steps t. The resulting images show how regions within an image diffuse into each other during denoising.

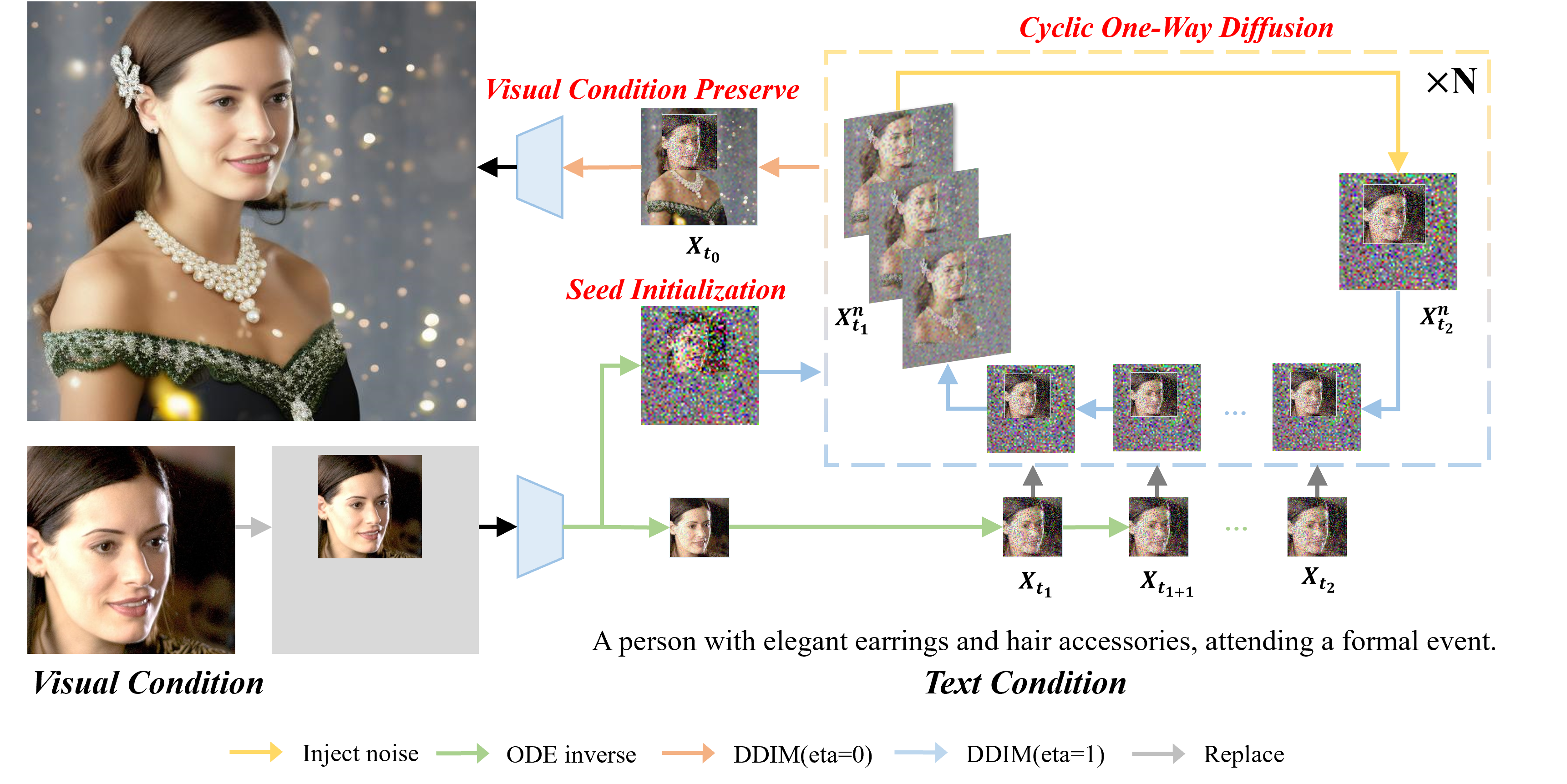
Given the input visual condition, we stick it on a predefined background and inverse it as the seed initialization of the starting point of the cycle. In the Cyclic One-Way Diffusion process, we “disturb” and “reconstruct” the image in a cyclic way and ensure a continuous one-way diffusion by consistently replacing it with corresponding xt.
COW strikes a balance between meeting the visual and text conditions. For example, when given a photo of a young woman but the text is “an old person”, our method can make the woman older to meet the text description by adding wrinkles, changing skin elasticity and hair color, etc. while maintaining the facial expression and the ID of the given woman.

COW offers a flexible change in the visual condition region according to the text guidance. The level of changes that may occur within the seed image depends on the discrepancy between textual and visual conditions. We show a set of samples containing gradual changes of the generated sample: (1) almost unchanged, (2) slightly perturbed (e.g., add accessories), (3) attribute variation (e.g., from smile to angry), (4) style transfer (e.g., from photo to comic picture), and (5) cross-domain transformation (e.g., from human face to lion). The results demonstrate that the seed images can be well preserved given no explicit conflict between the visual-text conditioning pairs, while appropriate levels of text-guided changes can also be well reflected in the case of attribute variation, style transfer, and cross-domain transformation.

We further provide examples with stronger conflicts (cross-domain transformation) to demonstrate the model could even fit in the case where the visual condition has a very strong conflict with other conditions.

COW can also be applied to whole image generation and editing.

COW can be directly applied to other visual conditions other than human faces.

@article{wang2023diffusion,
title={Diffusion in Diffusion: Cyclic One-Way Diffusion for Text-Vision-Conditioned Generatio},
author={Wang, Ruoyu and Yang, Yongqi and Qian, Zhihao and Zhu, Ye and Wu, Yu},
booktitle={The Twelfth International Conference on Learning Representations},
year={2023}
}
Acknowledgements: The website template is borrowed from DreamBooth.